Curve 文件系统为 AI 业务降本增效
背景
如今大数据和人工智能领域的快速发展,随着数据量的爆炸式增长,对底层文件存储的扩展性、成本和性能提出了更高的要求。特别在 AI 业务场景下,文件系统面临一些新的变化:POSIX 接口兼容、文件共享、海量小文件、数据读多写少等。
Why Curve?
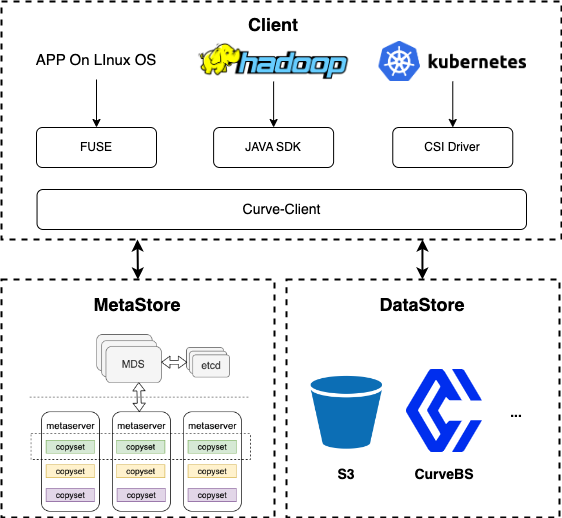
1. 接口兼容
Curve 文件系统同时支持 POSIX、HDFS和K8s CSI 接入方式,可以满足 AI 场景下业务存储的无缝替换。
2. 横向扩展
随着文件数量的增长,现有的文件系统如 CephFS 和 HDFS 等元数据的可扩展性不足,无法满足大规模文件存储的需求。Curve 文件系统自研的元数据引擎可横向扩展,解决元数据管理的问题。
Curve 文件系统原数据引擎具有高可用、高可靠和高可扩的特点,数据的可靠性和可用性通过 Raft 协议保证,元数据经过分片均匀分散在不同的 Raft-Group 中,保证了数据和负载的均衡性,同时支持业务按需进行一键弹性扩缩容。
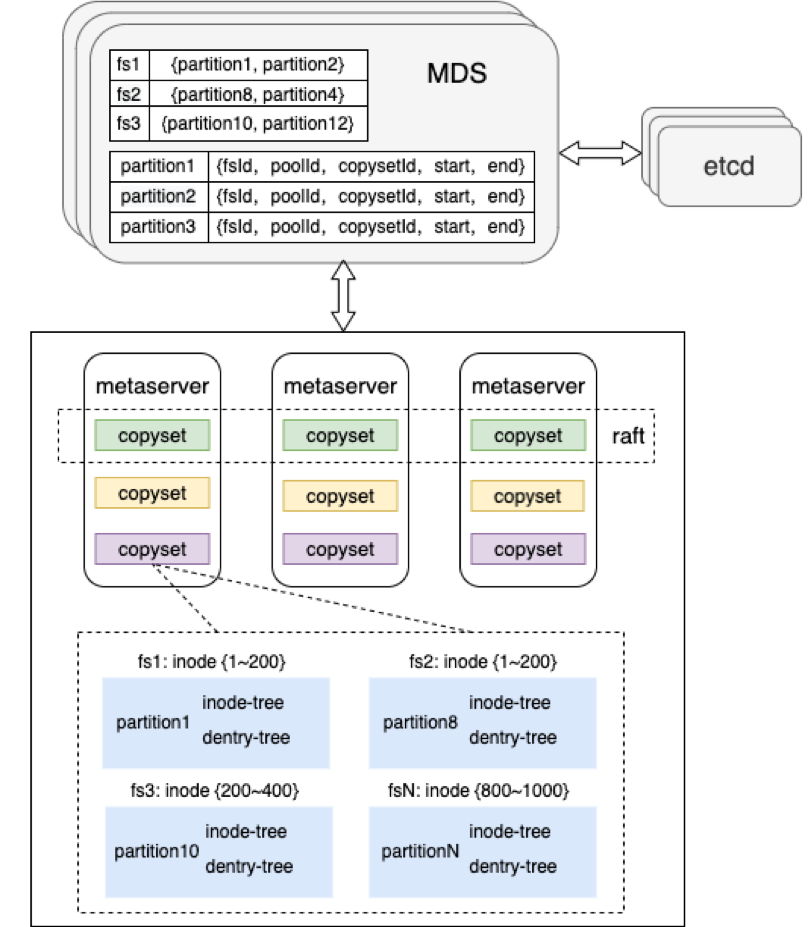
3. 高性能
随着文件数量的增加,传统文件系统元数据的性能会大幅下降,此外,小文件的读写性能也比较差,这会对大数据和AI等业务产生影响。Curve文件系统通过多级缓存机制,提高文件元数据访问性能,并改善小文件的读写性能。
3.1 元数据缓存机制
元数据支持内核和本地的多级缓存,并提供灵活的缓存配置,用户可以根据自己业务的特点配置合适的缓存失效时间,以在满足一致性要求的前提下获取更高的操作性能。此外,通过结合VFS层的重试机制,Curve 文件系统提供了完善的 CTO(close-to-open)一致性。
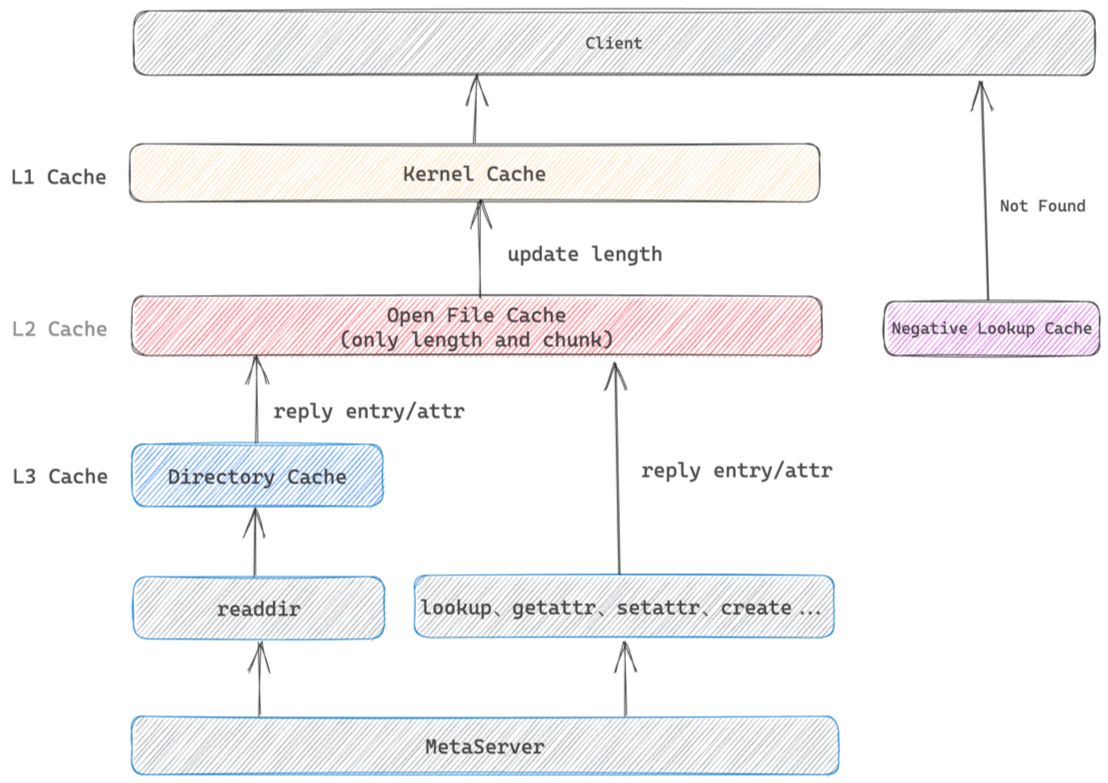
Kernel Cache -> 通用缓存
fs.kernelCache.attrTimeoutSec=3600
fs.kernelCache.dirAttrTimeoutSec=3600
fs.kernelCache.entryTimeoutSec=3600
fs.kernelCache.dirEntryTimeoutSec=3600
Open File Cache -> 文件读写
fs.openFile.lruSize=65536
Negative Lookup Cache -> 代码编译/SO查找/所以命令
fs.lookupCache.negativeTimeoutSec=1
fs.lookupCache.minUses=3
Directory Cache -> 大目录/ls、find
fs.dirCache.lruSize=5000000
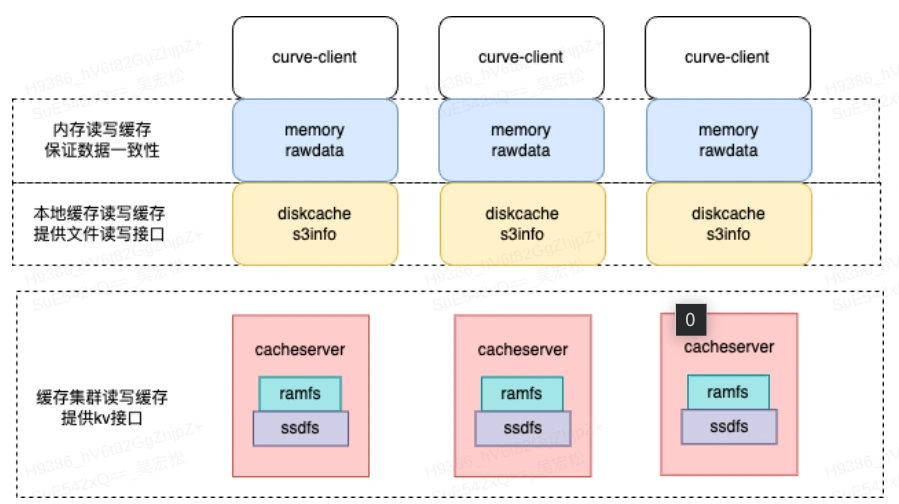
3.2 数据缓存机制
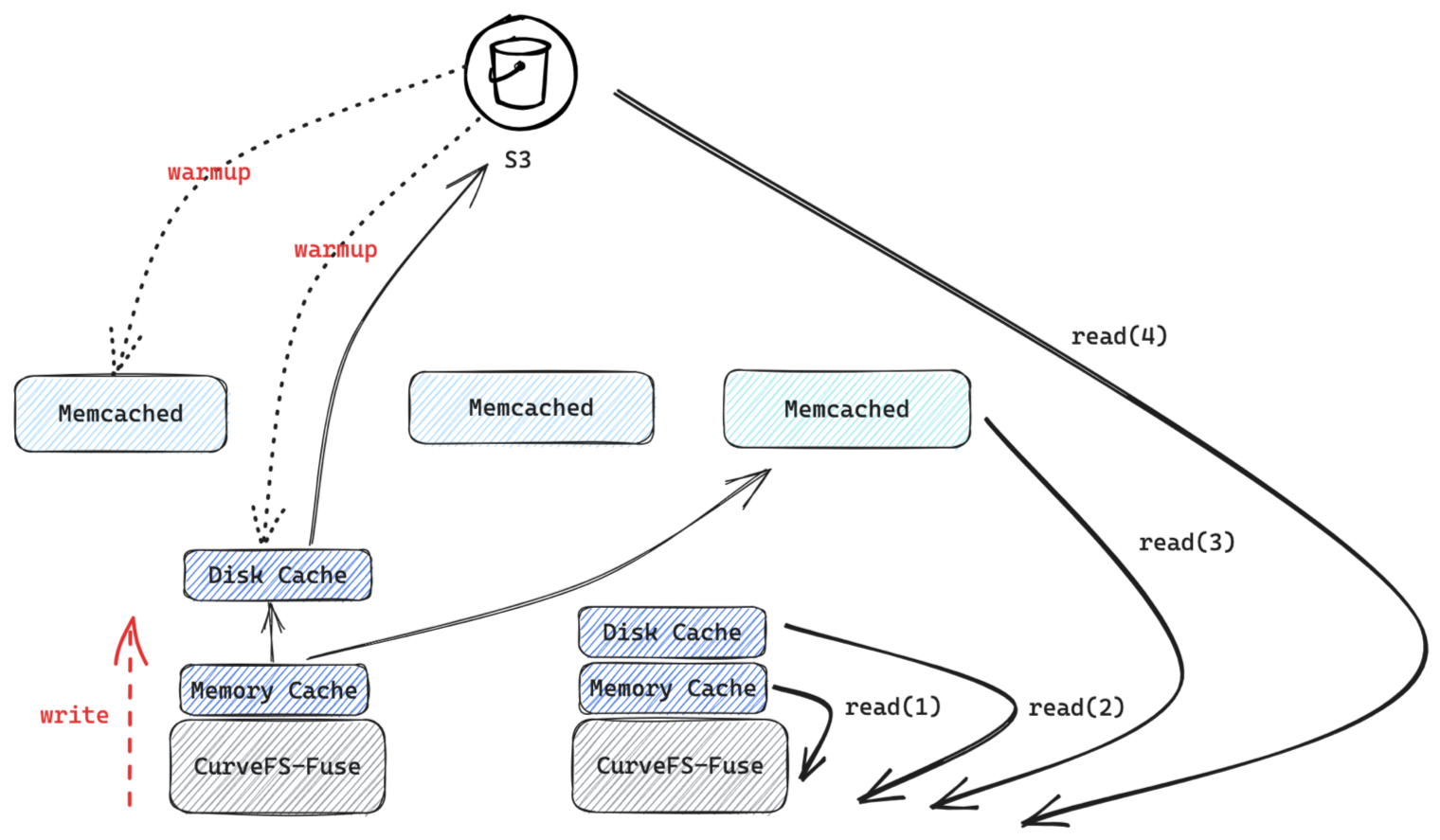
数据层面 Curve 文件系统同样支持可配的内存缓存、本地磁盘缓存和分布式缓存集群来加速数据的访问。
- 内存缓存:用于加速当前节点上的读写速度(sync操作时会刷到持久化存储保证数据可靠性)。
- 本地磁盘缓存:用于加速当前节点上的读写速度(开启共享(cto)时,数据会同时刷一份到共享缓存中,如果没配置共享缓存则需要上传到后端数据存储引擎)。
- 共享缓存:用于加速跨节点间的数据共享速度。
为了加速数据的读取速度,Curve 文件系统支持数据的预读和预热。
预读(prefetch):即在数据访问时,可以将文件超过访问长度外的数据提前读入缓存,提高后续读请求缓存命中率。
预热(warmup):指用户在使用到某部分数据之前主动的触发该部分数据写到指定缓存层,提高使用时的性能,例如在 AI 训练场景下,可以提前将训练数据集预热到缓存中,来加速整个训练过程。
降本增效成果
网易杭研多媒体团队 AI 业务之前使用三副本 Ceph 内核文件存储来支撑AI场景,包括通用、AI相关的各种流程。AI 业务存储的数据量是巨大的,但其中 80% 都是冷数据,使用三副本存储成本很高。业务期望找一个文件系统能无缝替换 Ceph,且在保证性能的同时能够降低存储成本。
目前网易杭研多媒体 AI 业务已全量迁入 Curve 文件系统,业务使用后的收益包括:
成本下降:Curve 文件系统后端接入网易对象存储(NetEase Object Storage)低频存储,相比3副本存储每年每 PB 数据存储可节约75%成本。
性能提升:在通用场景 Curve 文件系统性能和 Ceph 内核文件系统差不多持平,在 AI 存储密集型的特征提取和部分特征训练场景性能提升30%+,计算密集型特征训练场景性能和Ceph内核文件系统持平。尤其是在昂贵的GPU节点上,存储性能提升可以带来更高的GPU利用效率,从而降低训练成本。
提升训练任务并发度:使用 Ceph 文件系统作为 AI 训练数据集存储后端时,所有数据需要实时从存储后端读取,一旦业务有多个AI任务需要并发执行,就会导致 Ceph 文件系统存储后端负载超出集群总能力,最终导致训练任务耗时大大拉长。Curve 文件系统通过利用多级缓存加速能力,大部分训练数据只需要从存储后端读取一次即可缓存到本地或分布式缓存集群,从而降低对存储后端的性能需求,把负载分散到训练节点或分布式缓存集群,极大提升训练任务的并发度,减少多个训练任务之间的互相影响。
后续规划与展望
Curve 作为一个年轻的文件系统,仍在快速迭代发展中,后续将继续聚焦在 AI 、大数据存储等场景:
- 进一步优化元数据和数据读写性能,为支持更多应用场景打好基础。
- 和 AI 框架的融合,做到⾃动预热、训练节点和缓存节点的亲和性调度、与各类算法平台的深度融合等,进一步提升AI训练场景下的易用性和性能表现。